%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Identity Preservation
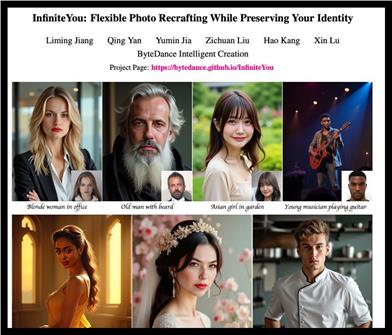
Infiniteyou
InfiniteYou (InfU) is a powerful diffusion-transformer-based framework designed for flexible image reconstruction while preserving user identity. By introducing identity features and employing a multi-stage training strategy, it significantly improves the quality and aesthetics of image generation while enhancing text-to-image alignment. This technology is important for improving the similarity and aesthetics of image generation and is suitable for various image generation tasks.
Image Generation
76.7K

Colorflow
ColorFlow is a model designed for coloring image sequences, with a particular focus on preserving the identity of characters and objects during the coloring process. Utilizing contextual information, it accurately generates colors for different elements (such as hair and clothing) in black-and-white image sequences based on a pool of reference images, ensuring consistency with the color references. Through a three-phase diffusion model framework, ColorFlow introduces a novel retrieval-augmented coloring workflow that achieves relevant image coloring without the need for fine-tuning each identity or extracting explicit identity embeddings. Its main advantages include high-quality coloring effects while retaining identity information, which is of significant market value for coloring cartoon or comic series.
Image Editing
50.0K
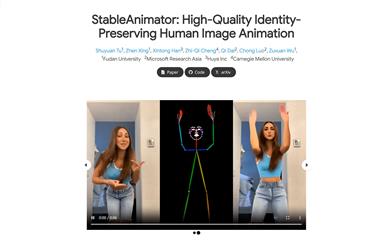
Stableanimator
StableAnimator is the first end-to-end identity-preserving video diffusion framework that synthesizes high-quality videos without the need for post-processing. This technology ensures identity consistency through conditional synthesis based on reference images and a series of poses. Its main advantage is that it does not rely on third-party tools, making it suitable for users who need high-quality portrait animations.
Video Production
67.3K

Diffusion Self Distillation
Diffusion Self-Distillation is a self-distillation technique based on diffusion models for zero-shot custom image generation. This technology allows artists and users to generate their own datasets via a pre-trained text-to-image model without requiring large paired datasets, enabling them to fine-tune the model for image-to-image tasks conditioned on text and images. This approach surpasses existing zero-shot methods in maintaining performance on identity generation tasks and can rival instance-based tuning techniques without the need for optimization during testing.
Image Generation
102.9K

Consisid
ConsisID is a frequency decomposition-based identity-preserving text-to-video generation model that generates high-fidelity videos consistent with the input textual descriptions using identity control signals in the frequency domain. This model does not require tedious fine-tuning for different cases and is capable of maintaining consistency in character identity within the generated videos. The introduction of ConsisID advances video generation technology, particularly in terms of streamlined processes and frequency-aware identity preservation control schemes.
Video Production
55.2K

Disenvisioner
DisEnvisioner is an advanced image generation technology that creates customized images by separating and enhancing thematic features, eliminating the need for tedious adjustments or reliance on multiple reference images. This technology effectively distinguishes and enhances thematic features while filtering out irrelevant attributes, achieving exceptional personalization in terms of editability and identity preservation. The research basis of DisEnvisioner stems from the current demand in the field of image generation for extracting thematic features from visual cues, tackling challenges faced by existing technologies through innovative approaches.
AI image generation
50.8K
Stableidentity
StableIdentity is a latest advancement based on large pre-trained text-to-image models, capable of achieving high-quality, human-centric generation. Unlike existing methods, StableIdentity ensures the stable retention of identity and flexible editability, even when training is conducted using only one facial image of each subject. It utilizes a facial encoder and identity prior to encode the input face, then projects the facial representation into an editable prior space. By combining identity priors and editability priors, the learned identity can be injected into various contexts. Additionally, StableIdentity incorporates a masked two-stage diffusion loss to enhance pixel-level perception of the input face and maintain the diversity of generation. Extensive experiments demonstrate that StableIdentity outperforms previous customization methods. The learned identity can also be flexibly combined with existing modules like ControlNet. Notably, we are the first to directly inject identities learned from a single image into video/3D generation without fine-tuning. We believe that StableIdentity is an important step towards unifying image, video, and 3D customization generation models.
AI image generation
65.4K
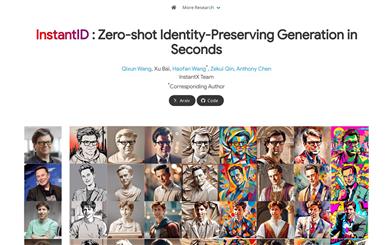
Instantid
InstantID is a solution based on powerful diffusion models that enables personalized image processing of a single face image across various styles while ensuring high fidelity. We designed a novel IdentityNet that, through the application of strong semantic and weak spatial constraints, integrates face and landmark images with textual prompts to guide image generation. InstantID performs remarkably well in practical applications and can seamlessly integrate with popular pre-trained text-to-image diffusion models (such as SD1.5 and SDXL) as an adaptable plugin. Our code and pre-trained checkpoints will be provided at [URL].
AI image generation
619.6K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.0K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.4K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
41.7K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
42.8K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.4K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.0K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.1K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M